Ultra fast HashTable (Dictionary) with direct indexing

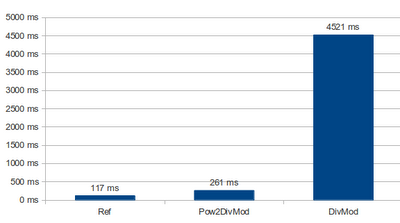
One of the most common usages of hash tables is to count/group occurrences of different elements in it, something like this: dict[“key”]++ . The direct access hash table outperforms any generic implementations, even though hash tables are supposed to be excellent at this task. Although this operation is considered to be constant time ( O(1) ), the generic implementations of dictionaries do an unnecessary step: double hashing of the key. If we look at the disassembled code of the example above, this is what happens in the background (.NET ILDASM simplified code snippet): get_Item(!0) // retrieve the item using the key (hashing happens) ldc.i4.1 // store the result integer add // increment the integer set_Item(!0,!1) // store the new value with the original key (hashing happens) Generally hashing is fairly quick, however, if the key is a string for instance, the hash function has to check every character of the string to create the hash value, which is an integer. The CPU is reall...