Detecting language features and building machine translation based on sample bilingual corpus
Representing the language as a directed graph can give us insights on how the language is structured, what are the typical phrases and potentially, if this graph can be matched to another graph in a different language, automatically build up a machine translation graph.
Let's say we analyse the following two simple sentences:
"The cat is brown."
"Don't play with the cat."
These would yield the following directed graph:
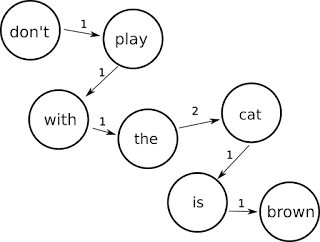
As we can see the transition from "the" node to the "cat" node has a weight of 2 because in this sample the most likely transition from the word "the" is to the word "cat".
Given large enough text corpus the typical phrases in a language would become obvious and if we give correct weights to the transitions while removing the noise the graph would actually be meaningful.
The first task was to obtain a large enough homogeneous corpus in preferably two different languages to train the sample. The Gutenberg project is a very good source for quality corpuses and I picked a classic one, Don Juan.
As the source was in HTML I used BeautifulSoup to parse out the Spanish and English translations and used a simple python script to build the weighted directed graph (source code at the end).
Having a lot of pairs expressed as "Don -> Juan, 34" wasn't really useful to the human eye, so I used Graphviz to draw the graph from the potential transitions, ignoring the less likely ones. So for instance, if in the corpus I only found "la -> mesa" transition less than 5 times, I ignored it, making the resulting graph more meaningful.
Graphviz dot tool does take the weights into account, so if a weight is higher it will move the nodes closer to each other, and the results were more than meaningful! The python script, that had no idea what a language is and had no other information just the text yielded surprisingly good insights on the structure of a language.
The other idea was that if I can find a clear phrase to phrase transition enough times in the corpus I can consider that a valid translation. Unfortunately, the mapping between the source and destination phrases within a sentence is quite difficult, so I cut some corners for this specific exercise: only a full sentence or line to another full sentence or line is considered to be a valid mapping.
As it was expected, this approach did not uncover too many translations, but the ones it did were actually accurate! Again, all this without any dictionaries or prior knowledge about the source or the destination languages. I used Spanish and English in this case because I happen to speak both so I can verify the correctness of the approach, but I could have used Korean and French and the results would be equally accurate.
The next step will be to try to iteratively build up the translation of the phrases, starting from the simple 1:1 word mapping then moving on the 1 & 2 words : 1 & 2 words type of mapping and so on. The idea is that once we understand that both "el" and "la" is mapped to "the", it's easier to understand that the phrase "la mesa" means "the table".
The first version that I've written yielded too noisy output so it definitely needs further refinements; having said that, it did find many translations that the previous sentence/line level translation did not uncover.
Language as a graph
Let's say we analyse the following two simple sentences:
"The cat is brown."
"Don't play with the cat."
These would yield the following directed graph:

As we can see the transition from "the" node to the "cat" node has a weight of 2 because in this sample the most likely transition from the word "the" is to the word "cat".
Given large enough text corpus the typical phrases in a language would become obvious and if we give correct weights to the transitions while removing the noise the graph would actually be meaningful.
Analysing Don Juan
The first task was to obtain a large enough homogeneous corpus in preferably two different languages to train the sample. The Gutenberg project is a very good source for quality corpuses and I picked a classic one, Don Juan.
As the source was in HTML I used BeautifulSoup to parse out the Spanish and English translations and used a simple python script to build the weighted directed graph (source code at the end).
Having a lot of pairs expressed as "Don -> Juan, 34" wasn't really useful to the human eye, so I used Graphviz to draw the graph from the potential transitions, ignoring the less likely ones. So for instance, if in the corpus I only found "la -> mesa" transition less than 5 times, I ignored it, making the resulting graph more meaningful.
Graphviz dot tool does take the weights into account, so if a weight is higher it will move the nodes closer to each other, and the results were more than meaningful! The python script, that had no idea what a language is and had no other information just the text yielded surprisingly good insights on the structure of a language.
 |
| Crop of Spanish structure - 1 |
 |
| Crop of Spanish structure - 2 |
Translation between languages
The other idea was that if I can find a clear phrase to phrase transition enough times in the corpus I can consider that a valid translation. Unfortunately, the mapping between the source and destination phrases within a sentence is quite difficult, so I cut some corners for this specific exercise: only a full sentence or line to another full sentence or line is considered to be a valid mapping.
As it was expected, this approach did not uncover too many translations, but the ones it did were actually accurate! Again, all this without any dictionaries or prior knowledge about the source or the destination languages. I used Spanish and English in this case because I happen to speak both so I can verify the correctness of the approach, but I could have used Korean and French and the results would be equally accurate.
| Automatic translations found from Spanish to English |
Further work
The next step will be to try to iteratively build up the translation of the phrases, starting from the simple 1:1 word mapping then moving on the 1 & 2 words : 1 & 2 words type of mapping and so on. The idea is that once we understand that both "el" and "la" is mapped to "the", it's easier to understand that the phrase "la mesa" means "the table".
The first version that I've written yielded too noisy output so it definitely needs further refinements; having said that, it did find many translations that the previous sentence/line level translation did not uncover.



Comments
Post a Comment